All Articles
Explore our comprehensive collection of insights, case studies, and best practices across cybersecurity, DevOps, and observability.
Showing 14 articles
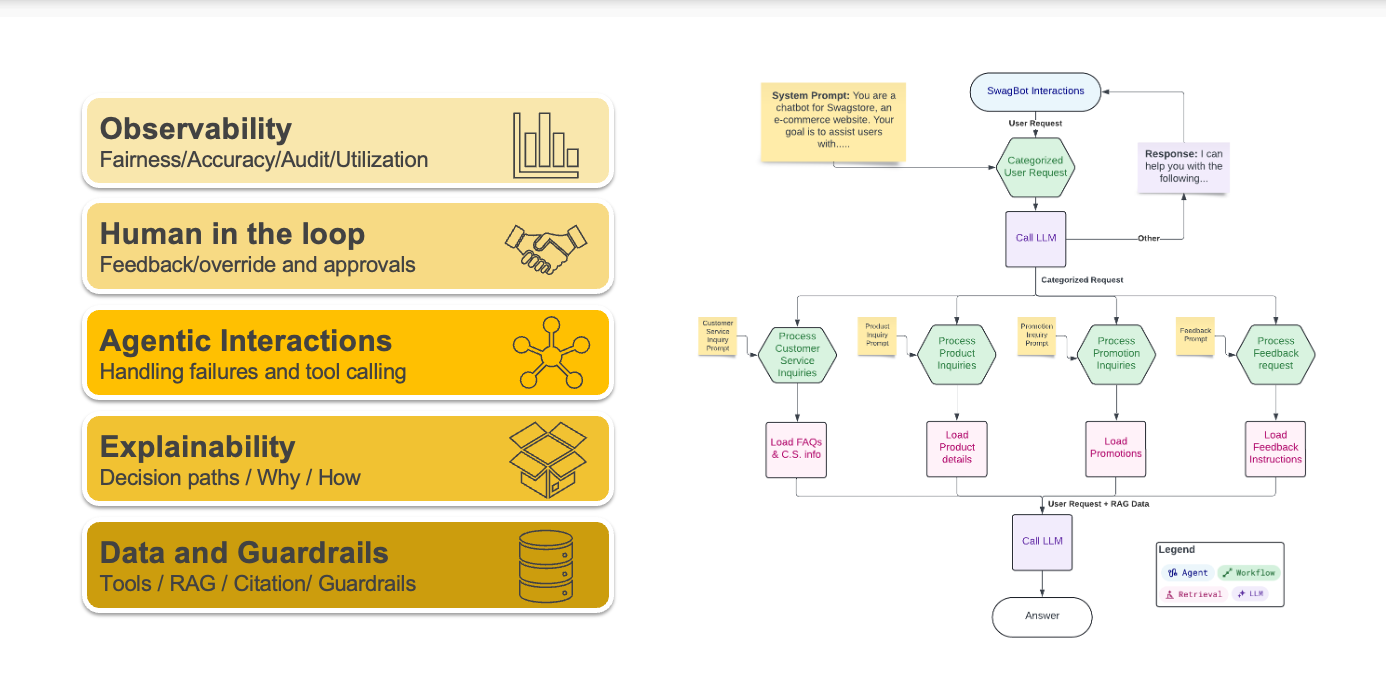
Deploying AI systems with Robust Governance
Enterprises are rapidly integrating AI into their workflows, but deploying these systems at scale brings new governance and compliance challenges. AI platforms must balance agility with oversight—ensuring cost efficiency, security, and predictability as they evolve. Through discussions with customers on AI adoption, several recurring pain points emerge across the deployment journey. In this post, we break down the common challenges and share practical approaches for building an AI governance architecture that is cloud-agnostic, scalable, and adaptable across both public clouds and on-premises environments.
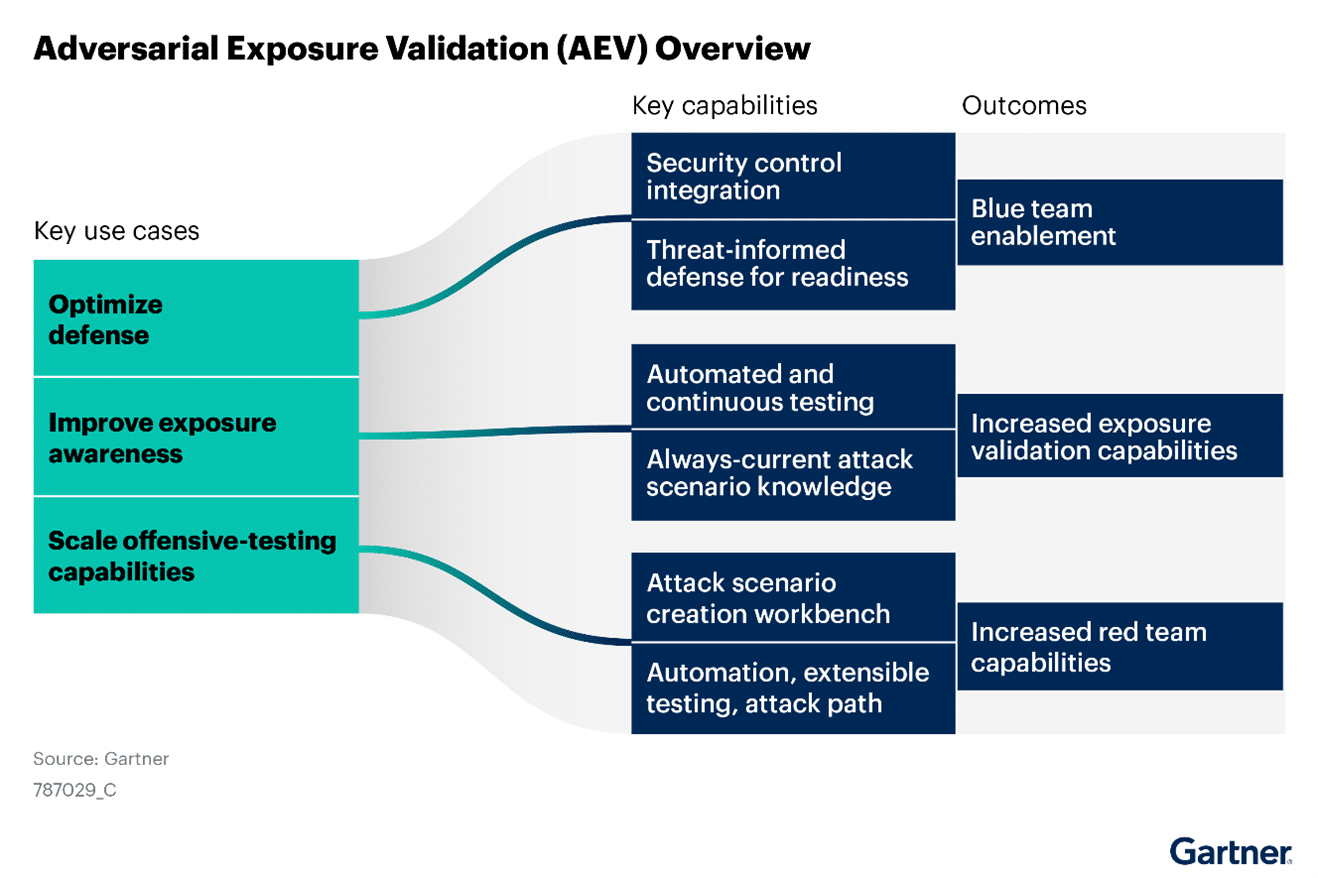
The Shift from Passive Response to Active Validation
Adversarial Exposure Validation (AEV) technology helps organizations validate their defensive posture against attack scenarios and techniques. It enhances exposure awareness, improves attack scenario readiness, and supports continuous threat exposure management.
The Disruptive Effects of Mobile Application Outages on Large Enterprises in Hong Kong
In today"s digital age, mobile applications are essential for large enterprises to connect with customers and drive growth. However, even the most meticulously tested apps can experience outages, leading to significant consequences for both users and the organizations behind them.

The build-or-buy dilemma in Feature Management
Organizations invest significant time, often months or even years, into modern application development life cycles. However, deployment can feel like a pivotal moment. While many Continuous Integration/Continuous Deployment (CI/CD) practices aim to simplify and reduce the stress of deployment by making it a regular occurrence, it can still pose substantial challenges and lead to various issues.
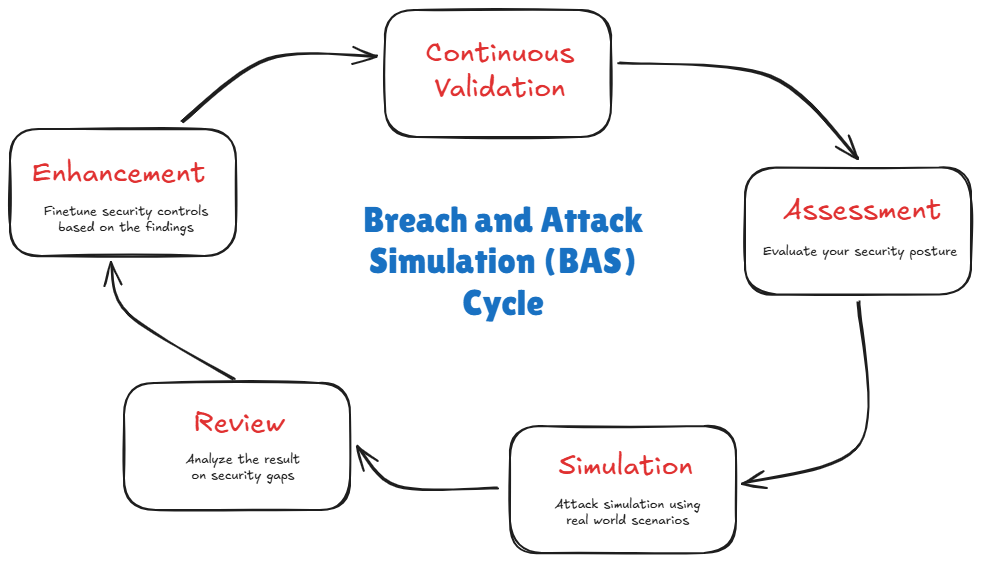
Validating your cyber defence effectiveness through Breach and Attack Simulation (BAS)
BAS is a proactive approach that automates the process of simulating cyber attacks such as phishing campaigns, malware, or exfiltration, to name a few, and then evaluates the organization"s defences. The aim is continuous identification of vulnerabilities across different devices or systems, keep organization ahead of the evolving cyber threats and minimize the security gaps.
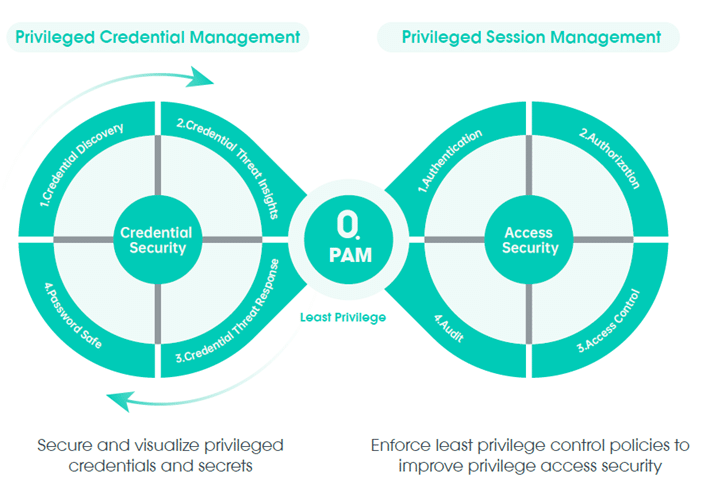
Securing Critical Infrastructure: Best Practices for Privileged Access Management (PAM)
In today"s digital landscape, protecting critical infrastructure is crucial for maintaining the stability of essential services. With increasing cyber threats targeting sectors like energy, banking, and healthcare, managing privileged access to critical systems has become more important than ever.
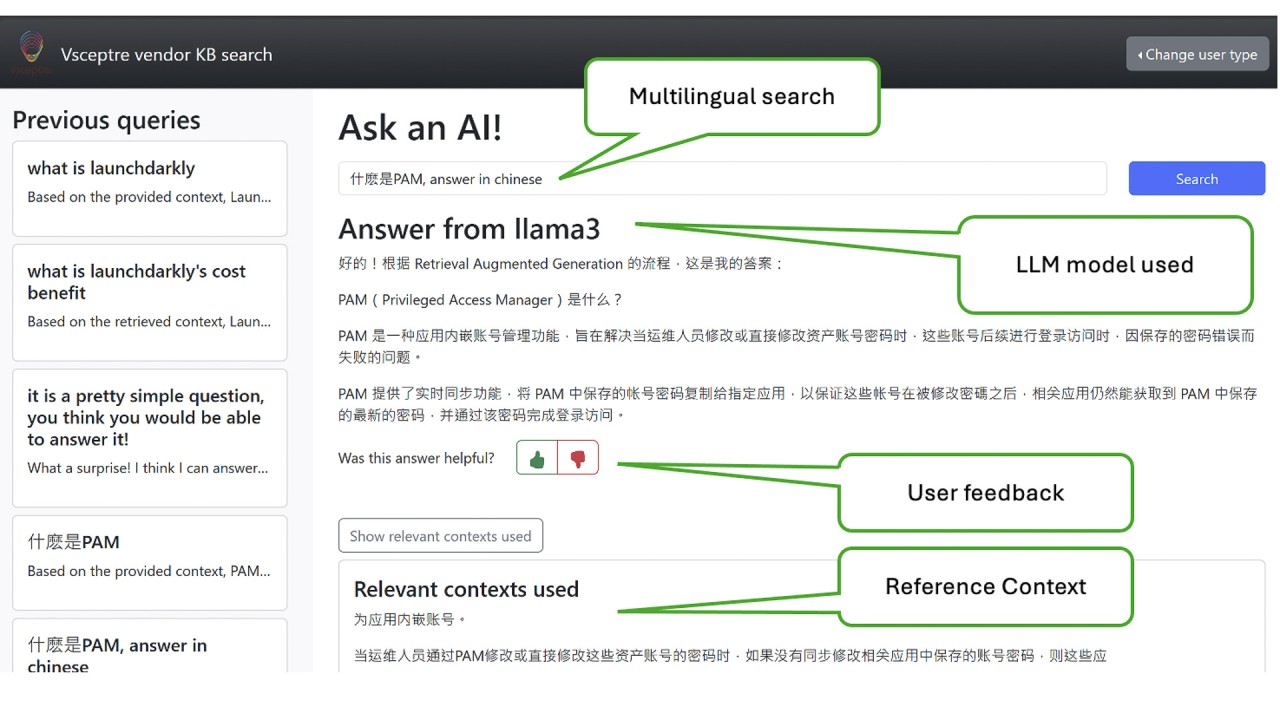
Implementing a production ready chatbot solution with governance and monitoring
As a company focused on IT consultancy and system integration, we have accumulated a large number of sales and solution briefs for various products over the past few years. We decided to implement an internal chatbot solution to better support sales activities.
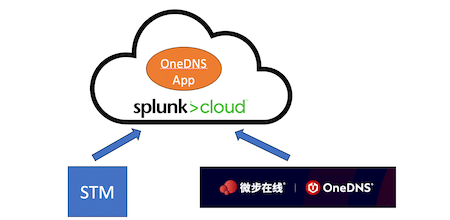
Uncovering Suspicious Domain Access in a company Network with Threatbook"s OneDNS and Splunk Stream
As your trusted ally in fortifying digital defenses, we understand that it can be difficult to pinpoint the users who have accessed dubious domains within your network. This task can be even more daunting in a larger-scale environment where the underlying on-prem infrastructure is subject to strict limitations on modifications.

Demystifying Log to Trace correlation in DataDog
If you have a chance to attend any presentation or public seminars from the APM vendors, you may come across some demonstrations of how easily to jump from trace to log or log to trace to diagnose a slow API call. This is one of the key differentiation of using a siloed approach for monitoring vs true full stack visibility.
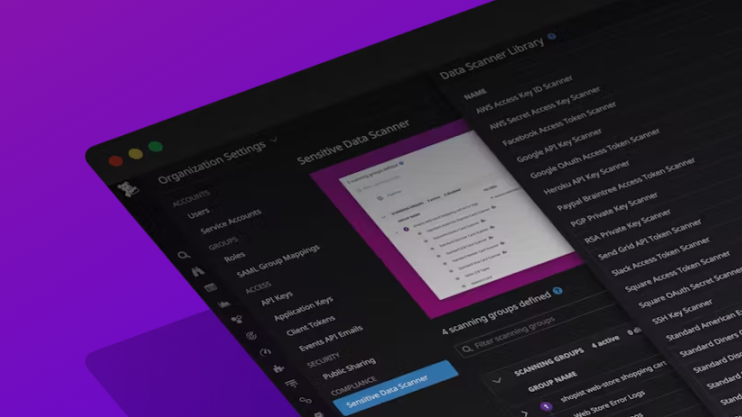
Log Sensitive Data Scrubbing and Scanning on Datadog
In today"s digital landscape, data security and privacy have become paramount concerns for businesses and individuals alike. With the increasing reliance on cloud-based services and the need to monitor and analyze application logs, it is crucial to ensure that sensitive data remains protected.

Monitoring temperature of my DietPi Homelab cluster with Grafana Cloud
At around end of March, I want to get my hands on the old raspberry pi cluster again as I need a testbed for K8S, ChatOps, CI/CD etc. The DevOps ecosystem in 2023 is more ARM ready compared with 2020 which makes building a usable K8S stack on Pi realistic.
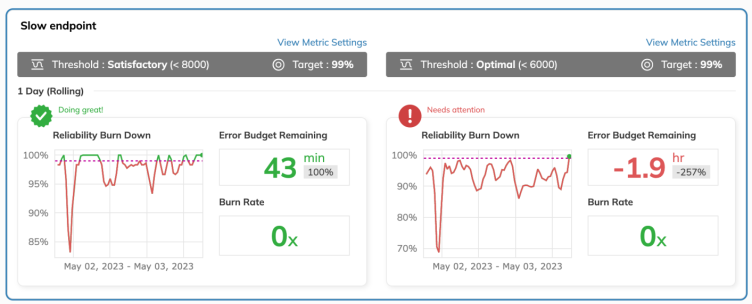
Setting up the first SLO
This is the final piece of the 3 part series "The path to your first SLO". We have discussed on the basics of what to observe and how to get the relevant metrics in part 1 and part 2 of this series. This time we are going to have a quick look on to setup a simple service availability monitoring SLO with Nobl9 and SolarWinds Pingdom.
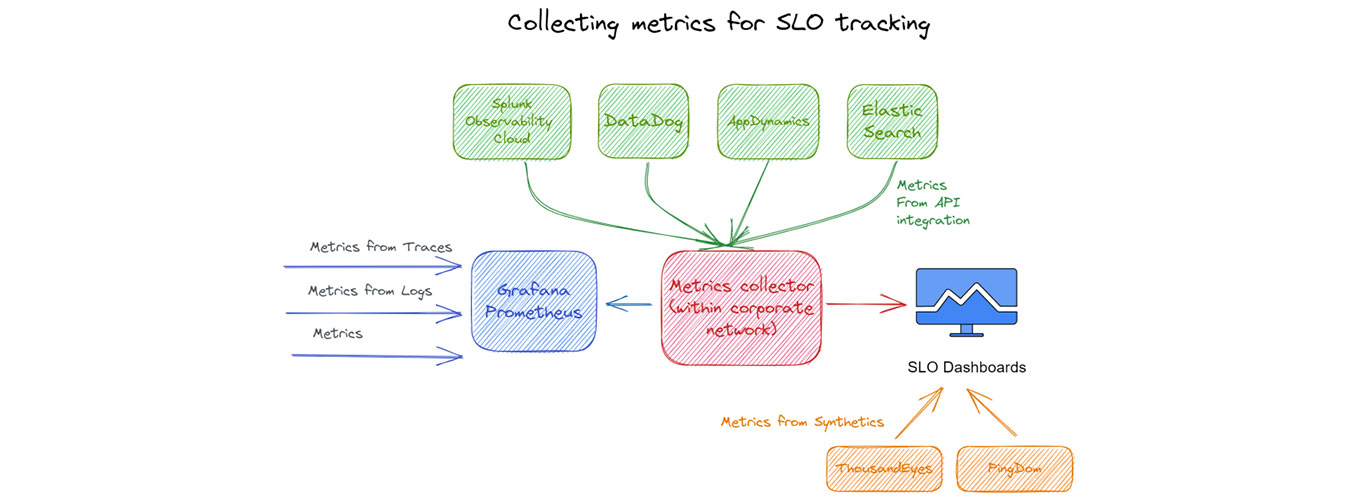
How to obtain the metrics for SLO tracking
This is part 2 of the 3 part series "The path to your first SLO". When you have a clear understanding of what metrics to gather for SLO, the next question is how to obtain and gather those metrics. Basically the metrics can be obtained by the following methods.
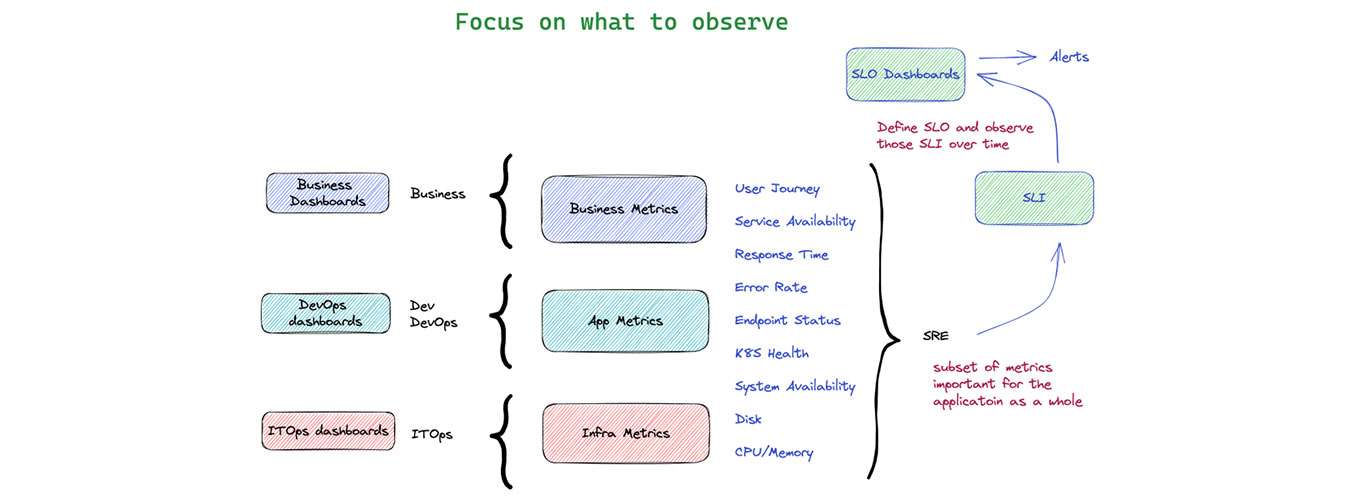
How to identify the golden metrics for SRE
This is part 1 of the 3 part series "The path to your first SLO". When talking about building an observability practice, many customers we talked to struggled on what to observe and usually frustrated with the alarm storms or false alarms. ITOps are concerned about centralized monitoring and gather metrics from different systems for proactive monitoring.