Implementing a production ready chatbot solution with governance and monitoring
In 2024, most organizations have already undergone the phase of conducting internal proof-of-concepts (POCs) to determine how generative AI (Gen AI) can streamline business processes. Today, CIOs face the challenge of bringing this technology into production while considering topics around cost, governance, and monitoring. There are numerous open source and vendor specific solutions to address the issue. For this post I want to share the journey of how to build a chatbot solution with responsible AI in mind.
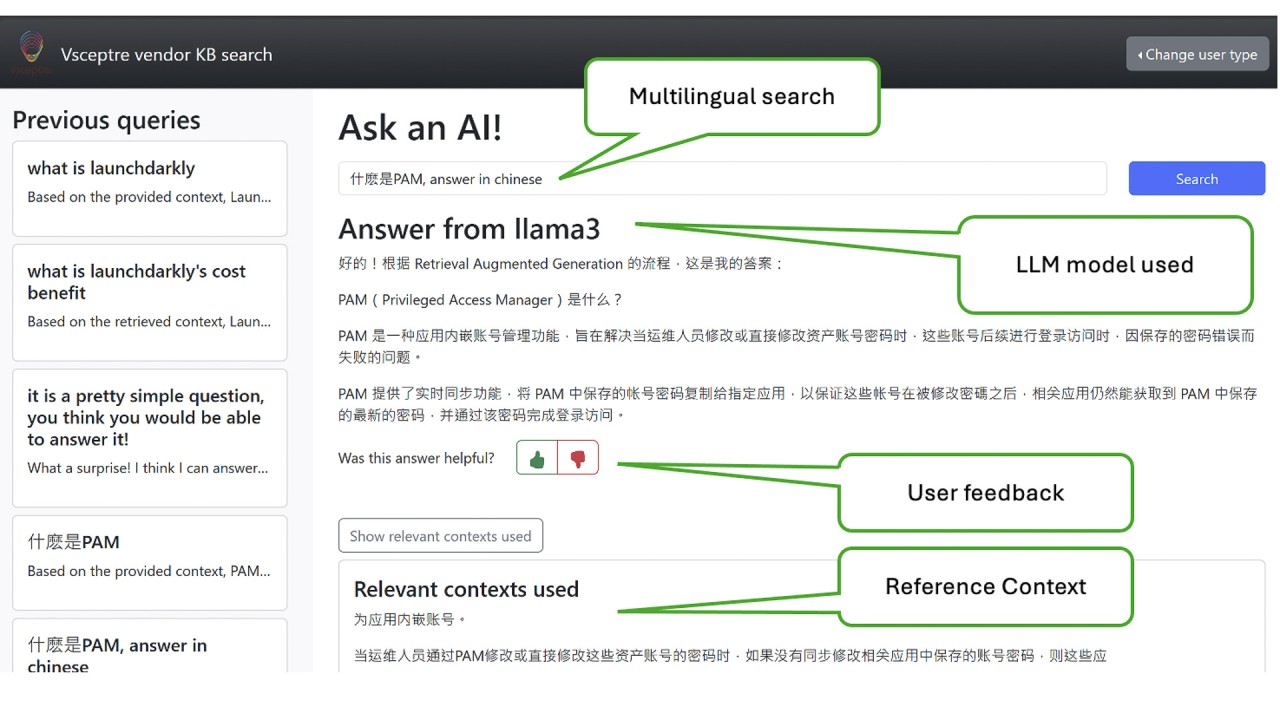
RAG-based chatbot architecture for enterprise sales support
Table of Contents
Introduction
As a company focused on IT consultancy and system integration, we have accumulated a large number of sales and solution briefs for various products over the past few years. We decided to implement an internal chatbot solution to better support sales activities. To minimize the investment required, we opted for a RAG approach instead of fine-tuning, building a chatbot solution based on a few products we are familiar with. Below is a high-level overview of how everything connects.
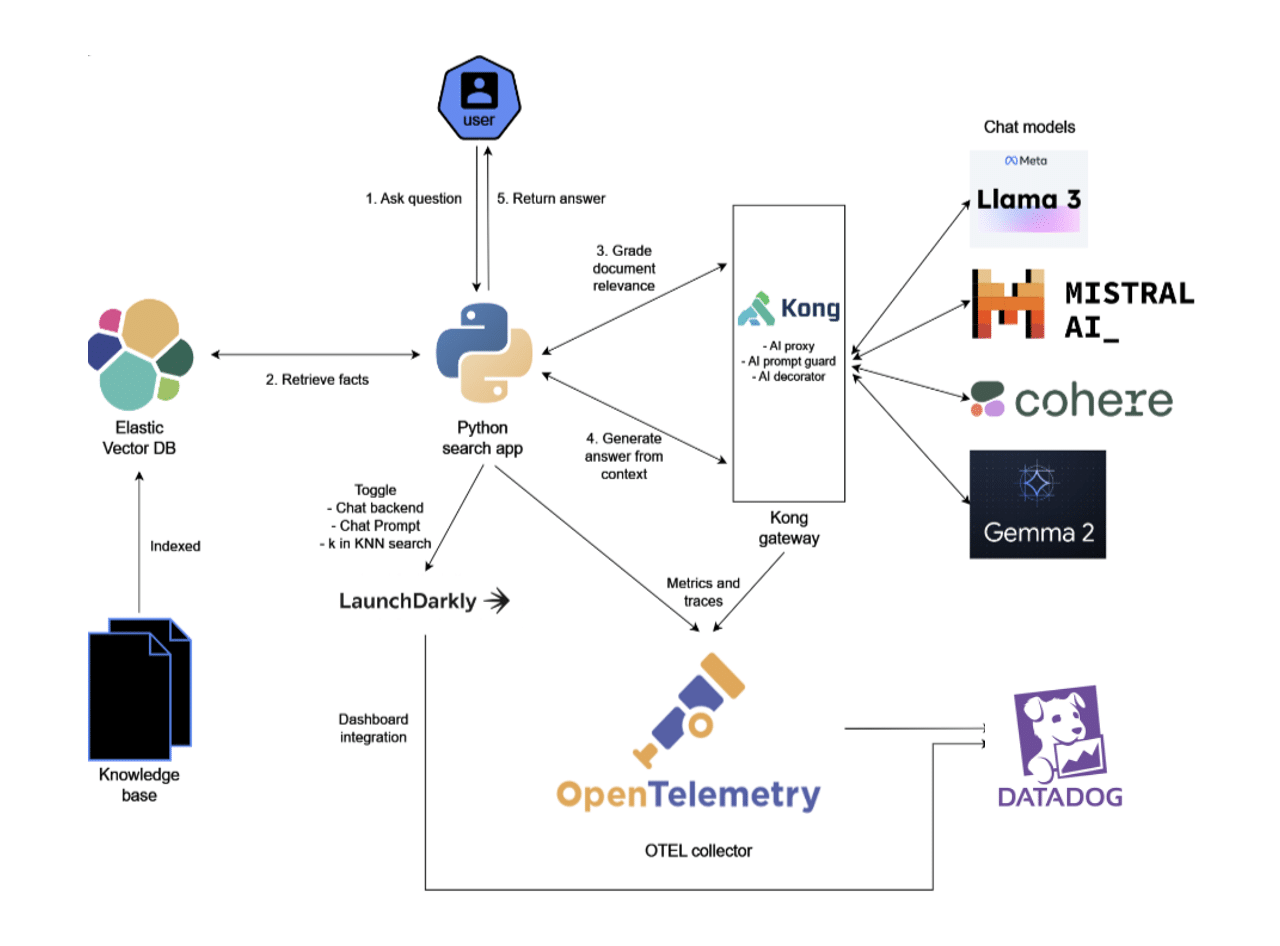
RAG chatbot architecture with ElasticSearch, Kong gateway, and multiple LLM models
A few components to highlight:
- ElasticSearch: Used for storing embeddings, functioning as a vector database and search engine.
- Kong: Serves as an AI gateway for governance and enforcement.
- Datadog: Act as the centralized monitoring tool for the Chatbot and LLMs.
- LaunchDarkly: Used for release and feature management.
Data Preparation
Internally we use 0365 to store all solution briefs and datasheets. Most of the documents are within gathered within the last 2 years so we didn't spend the time to identify and clean up redundant, obsolete, and trivial (ROT) data. If you need to find a a solution for cleaning up 0365 data sources, AvePoint Opus can be considered.
We generate embeddings by pointing the data source to the correpsonding sharepoint folder. Originally we use Elasticsearch only as a vector database to store the embeddings. Later we found that the top K results from the similarity search is not good enough as input for LLM. We decided to redo all the embeddings using ELSER V2 and using Elasticsearch for relevance search and results rankings. This provides much better results for LLM input.
Governance
We used Kong as the AI gateway or LLM proxy to connect with different LLM models. Kong provides a loosely coupled way to link the chatbot program with backend LLMs. This setup allows us to implement various types of LLM governance within Kong, such as prompt guards, decorators and request/response transformations. If we need to change a prompt template or swap to a different LLM, this can be easily accomplished in Kong. Metrics like token usage and API response times are captured and sent to Datadog for centralized monitoring.
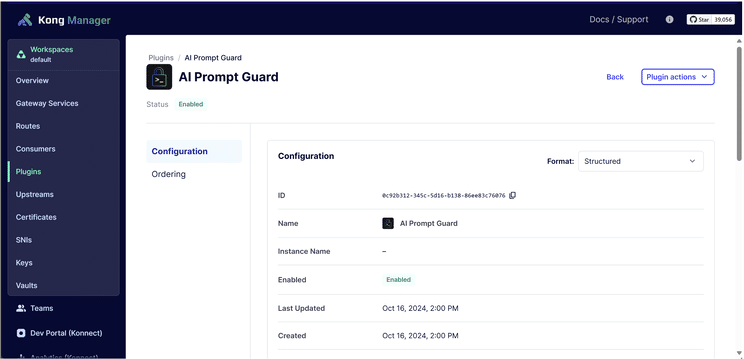
Kong AI Prompt Guard configuration for LLM governance and enforcement
Monitoring
Datadog is selected for LLM monitoring for our internal Chatbot. Datadog gathers metrics from Kong, the Python application, and the inputs/outputs from LLMs. We can easily monitor critical performance metrics such as LLM API response times, input and output tokens, and more. Soft metrics related to AI governance, such as toxicity, hallucination, and prompt ingestion are also monitored in Datadog. Kong and Datadog work nicely together on AI governance. In our case, Kong is mainly used for enforcement, while Datadog provides observability on the overall LLM performance. Datadog also provides comprehensive information on LLM interactions for audit purposes.
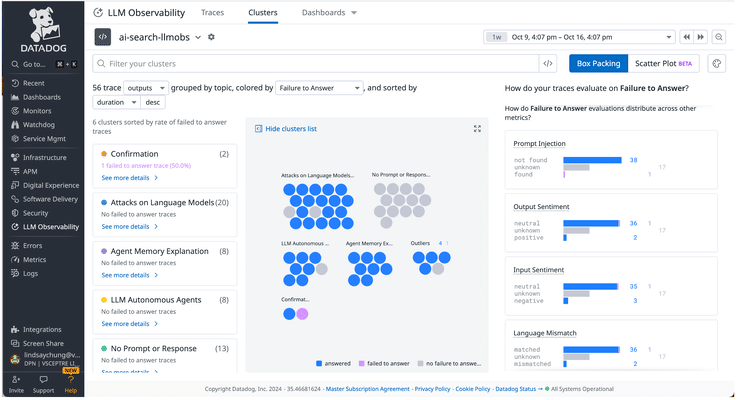
Datadog LLM Observability dashboard with clusters, traces, and failure analysis
Feedback Loop
We incorporated LaunchDarkly to implement a feedback loop. Feedback is collected directly from the Python program and through native LaunchDarkly integration with Datadog. To gather human feedback on model performance, we implemented a thumbs-up/down mechanism on the chatbot interface. These feedbacks are aggregated in Datadog, and both soft and hard metrics from the LLM are being used to toggle feature flags in the chatbot program. For instance, if an LLM experiences long response times or receives increased negative user feedback over a period of time we can automatically trigger feature flags to disable certain LLMs or swap prompt templates. This prevent costly rollbacks to a previous version of the app.
Currently, we manage prompt templates within LaunchDarkly using AI prompt flags, although this can also be handled in Kong. To compare model performance and Chatbot UI designs, we plan to integrate the program with SSO to support A/B testings.
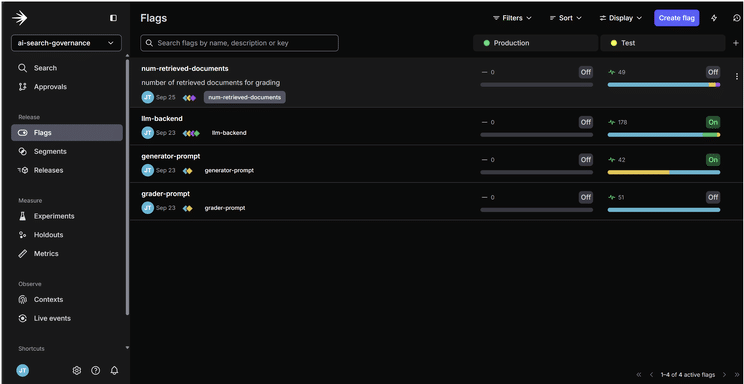
LaunchDarkly feature flags dashboard for chatbot backend and prompt management
Cost Considerations
We started with a local LLM model "llama3.1 8B" running on a single GPU. We want to save some money during the development phase. Also, some customers have to use an on-prem LLM due to strict company policies. This gives us and idea on whether a local model is good enough for our use cases. Later we added text models from AWS Bedrock for cost and output quality comparison.
Recently Kong announced a new feature on semantic caching, which aims to reduce LLM processing costs by intelligently caching prompts with similar meanings. We cant' wait to test this feature in our setup to further decrease LLM expenditures on Bedrock.
Conclusion
There are numerous ways to implement a chatbot; you can host everything within a cloud provider such as AWS or build everything in-house. If you need to fine-tune LLM models without managing the infrastructure, AWS can be a good option. For our use case, a local LLM model running on a single RTX 4070 GPU is more than sufficient. Regardless of where your LLM models are deployed, proper governance and guardrails should be implemented. Looking beyond cost and solution functionality, ensuring that LLM deployments adhere to the principles of responsible AI is crucial.
If you're interested in learning more, please don't hesitate to contact us: https://vsceptre.com/contact-us/
References
- https://www.elastic.co/search-labs/blog/introducing-elser-v2-part-2
- https://konghq.com/blog/product-releases/ai-gateway-3-8
- https://www.datadoghq.com/blog/datadog-llm-observability/
- https://launchdarkly.com/blog/introducing-ai-model–ai-prompt-flags/
- https://aws.amazon.com/blogs/machine-learning/a-progress-update-on-our-commitment-to-safe-responsible-generative-ai/
- https://cdn.avepoint.com/pdfs/en/brochures/Dedicated-brochure-on-Discovery-Analysis-tool-as-a-component.pdf
About Vsceptre
At Vsceptre, we connect people with technology. Our team of experts helps organizations implement AI-powered solutions and enterprise-grade chatbot systems to enhance operational efficiency and customer engagement.
Contact our specialist at charliemok@vsceptre.com to arrange a free one-on-one consultation session.
Related Articles
Uncovering Suspicious Domain Access in a company Network with Threatbook's OneDNS and Splunk Stream
As your trusted ally in fortifying digital defenses, we understand that it can be difficult to pinpoint the users who have accessed dubious domains within your network.
ObservabilityLog Sensitive Data Scrubbing and Scanning on Datadog
In today's digital landscape, data security and privacy have become paramount concerns for businesses and individuals alike.