Deploying AI systems with Robust Governance
Enterprises are rapidly integrating AI into their workflows, but deploying these systems at scale brings new governance and compliance challenges. AI platforms must balance agility with oversight—ensuring cost efficiency, security, and predictability as they evolve. Through discussions with customers on AI adoption, several recurring pain points emerge across the deployment journey. In this post, we break down the common challenges and share practical approaches for building an AI governance architecture that is cloud-agnostic, scalable, and adaptable across both public clouds and on-premises environments.
Table of Contents
1. Model Selection: Balancing Performance and Economics
The foundation of any AI deployment starts with selecting the right model hosting strategy. Many teams discover early that locally hosted models struggle to meet the computational demands of production-scale workloads—especially when reasoning complexity or request volume grows. Cloud-based models, in contrast, often deliver better economics by offloading the cost and maintenance of GPU infrastructure, auto-scaling, and model lifecycle management to providers.
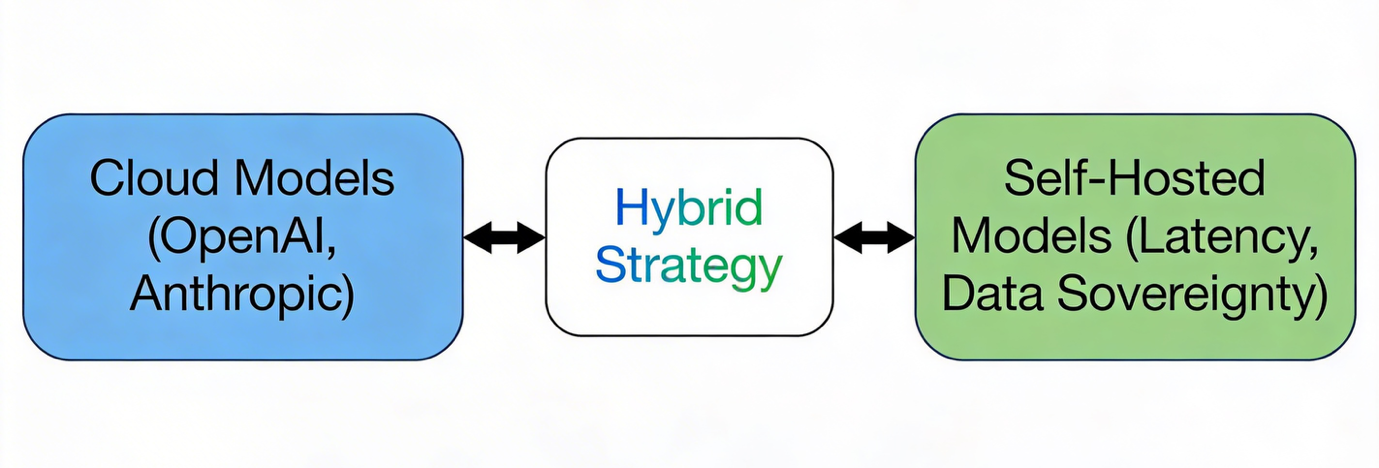
That said, debates around cost-per-token efficiency between local and cloud models remain ongoing. The most pragmatic approach is often a hybrid model strategy: leveraging cloud-based APIs for core reasoning capabilities while maintaining self-hosted deployments for scenarios that demand strict latency control or data sovereignty. This hybrid baseline ensures flexibility—providing enterprises the ability to scale while preserving governance over where and how data and models operate.
2. Standardizing Protocols Amid Framework Proliferation
Once model hosting is defined, the next challenge surfaces: the proliferation of AI frameworks. Over the past two years, the ecosystem has expanded rapidly, each framework optimizing for different use cases or model types. Without careful planning, this diversity can quickly lead to integration silos and operational friction.
Adopting standard communication protocols like MCP (Model Context Protocol)and A2A (Agent-to-Agent)helps decouple solutions from specific frameworks. Instead of tying long-term design decisions to a rapidly changing framework, MCP and A2A provide interoperability at the protocol layer. This approach enables seamless swapping between frameworks or model providers while preserving a unified governance structure. It’s the first step toward future-proofing your AI stack and simplifying cross-environment operations.
3. Implementing a Centralized Control Plane with AI Gateways
To facilitate teams to develop AI solutions with governance, we need an enforcement layer—this is where the control plane becomes central. A well-designed control plane acts as the policy and routing brain of your enterprise AI operations. It manages access controls, applies usage limits, and enforces compliance rules across teams and environments, while still allowing distributed teams to innovate independently.
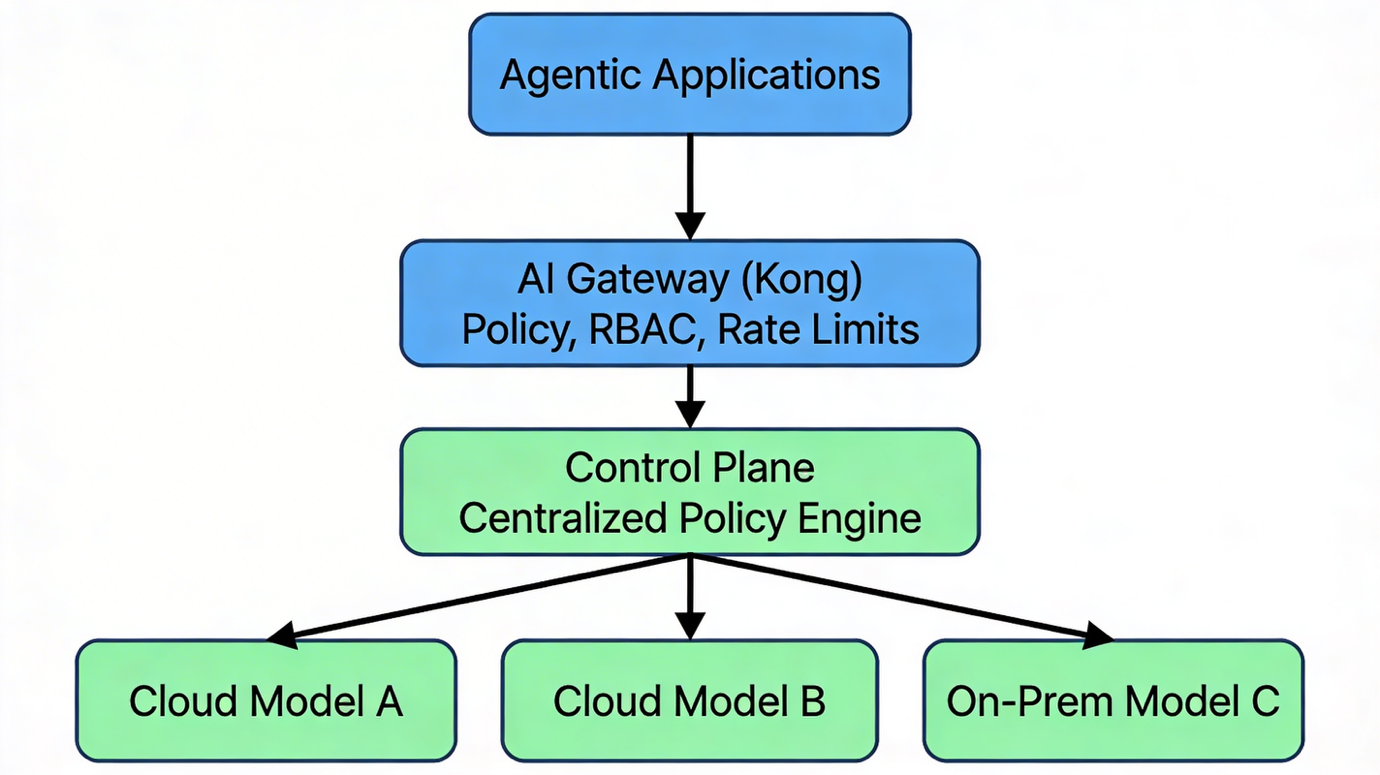
The control plane works hand-in-hand with AI gateways, which sit directly between agentic applications and underlying models. These gateways play a critical role in applying governance logic in real time—enforcing rate limits, ensuring data residency compliance, and dynamically routing traffic based on performance, cost, or compliance parameters.
Routing all model traffic through a central AI gateway such as Kong provides a single policy enforcement layer that can govern requests across Azure OpenAI, Anthropic, or self-hosted models. When integrated with enterprise identity systems (SSO, RBAC), it ensures traceability from user to model call—critical for compliance and auditability.
4. Building Comprehensive Observability
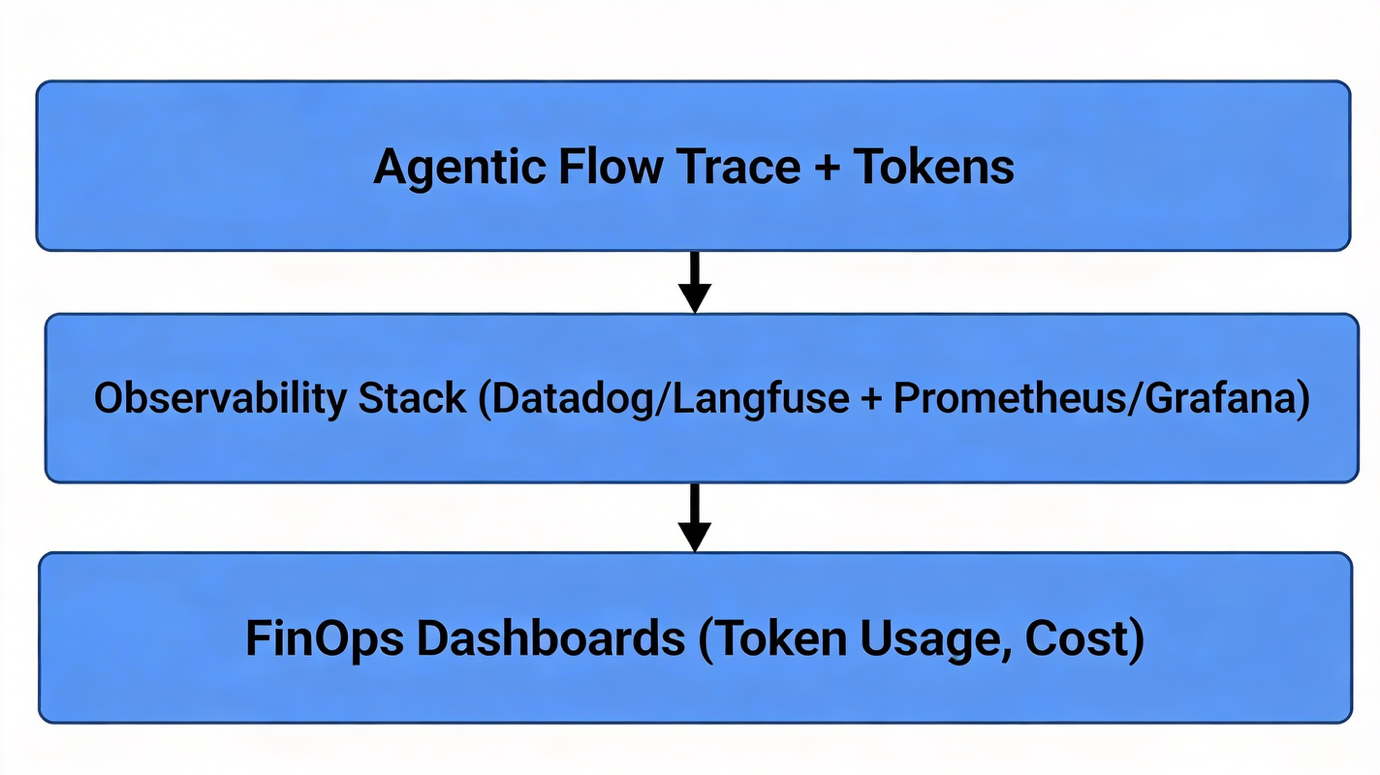
Once the routing and governance layers are in place, we can work on visibility. True AI observability goes beyond infrastructure metrics: it should captures token usage, inference latency, and gather model quality metrics like hallucination rate or response correctness. Observability also bridges to explainability—by tracing agentic flows, tool calls, and decisions through diagnostic spans, organizations gain deep insight into how outputs are produced.
This is where we found traditional application observability expanding into LLM observability. Commercial platforms like Datadog provide integrated LLM observability alongside traditional APM, enabling unified visibility through a single application SDK . For teams preferring self-hosted solutions, Langfuse combined with Elasticsearch(for logs), Prometheus(for metrics), and Grafana (for dashboards) forms a robust open-source stack. These observability layers also provides you with an answer for FinOps, allowing you to monitor token usage, user-level attribution, and application-level cost splitting benefited from an AI gateway.
Governance doesn’t stop at monitoring—it extends to optimization. By incorporating semantic caching at the AI gateway, repeated queries can be served efficiently with reduced token consumption. Quotas and throttling can further prevent unpredictable cost overruns while maintaining consistent performance expectations.
5. Post-Deployment Monitoring and Auditing
Observability data becomes truly powerful when tied into post-deployment auditing. By leveraging distributed traces from agentic and model interactions, teams can capture prompt context (securely redacted), token usage, latency, and policy outcomes for every request. This supports root-cause analysis during incidents and provides transparency into why agents generated specific decisions. In other words, we achieved explainability and audit trail by leveraging LLM distributed tracing.
Maintaining immutable audit logs—capturing agentic flow, model version, policy checks, and results—is essential for compliance. Elasticsearch serves well in this role, supporting on-prem deployments where regulatory or data-retention policies restrict external logging or cloud storage.
6. Proactive Evaluation and Risk Mitigation
Even with governance and observability in place, AI performance and integrity degrade over time if models aren’t continuously evaluated. Both cloud and fine-tuned models face issues like model drift, degraded quality, and unexpected responses. Deploying a continuous evaluation pipelines with CI/CD processes are crucial for detecting such regressions early.
Low-code workflow tools like n8n make it simple to build automated evaluation pipelines that incorporate RAGAS or other LLM-as-a-judge frameworks. Beyond quantitative evaluation, regular red teaming exercises help identify vulnerabilities such as prompt injection, sensitive data leakage, or policy circumvention. Integrating these findings into AI gateways ensures continuous tightening of pre-prompt and post-response filters without changing application logic—enabling adaptive governance in production.
While standard LLM evaluation measures typical performance on benchmarks like accuracy, fluency, or coherence using expected inputs, red teaming specifically uncovers adversarial weaknesses that standard tests miss. Conduct regular LLM red teaming to identify vulnerabilities such as prompt injection, data exfiltration, or harmful outputs. Operationalize findings by updating gateway-based filters for sensitive content, applying both pre-prompt and post-response safeguards consistently across all traffic.
Integrating both approaches ensures reliable, secure deployments—evaluation for capability, red teaming for resilience.
7. Agent Registry and Policy Enforcement
As enterprises expand their ecosystem of AI agents, managing them effectively becomes its own discipline. Agents are built with different frameworks and technology stacks and it can quickly run into chaos from a management perspective. A centralized agent registry helps standardize discovery, version tracking, and policy enforcement across teams. While most cloud vendors provide registries within their ecosystems, on-prem options are also available —for instance, Mistral AI Studio offers registry capabilities as part of the commercial AI suite suitable for private environment deployments.
A well-integrated agent registry links directly to the control plane and gateway, ensuring that every deployed agent inherits enterprise-wide governance and visibility policies automatically.
8. Conclusion
AI governance is no longer an afterthought—it’s a design principle. Building a governed, cloud-agnostic architecture involves more than policies on paper; it requires seamless integration of control planes, gateways, observability, evaluation pipelines, and registries into a coherent ecosystem.
The path forward is continuous: start with standardized protocols, enforce consistent access through gateways, instrument for observability, and iterate through evaluation. This end-to-end loop not only strengthens compliance and trust but also empowers innovation—allowing teams to scale AI safely across every environment.
About Vsceptre
Vsceptre provides observability solutions and consulting services to help companies achieve digital resilience through AI for observability—leveraging intelligent analytics, anomaly detection, and predictive insights to monitor complex systems proactively—and observability for AI, ensuring full visibility into LLM performance, agentic flows, token usage, and governance compliance across production deployments.
Vsceptre delivers integrated, enterprise-grade toolchains that combine cutting-edge monitoring with robust AI gateway controls, enabling scalable and secure AI operations.
For further information, contact Vsceptre at charliemok@vsceptre.com
Related Articles
The build-or-buy dilemma in Feature Management
Organizations invest significant time, often months or even years, into modern application development life cycles. However, deployment can feel like a pivotal moment.
ObservabilityImplementing a production ready chatbot solution with governance and monitoring
As a company focused on IT consultancy and system integration, we have accumulated a large number of sales and solution briefs for various products over the past few years.